AWS에서 서버리스를 만져본지 얼마되지 않았지만, DynamoDB에 데이터를 집어넣는 것이 쉽지 않아서 알아보았습니다.
준비물은 다음과 같습니다.
- 간단하게 csv 형태로 저장된 파일.
- S3 버킷
- 람다함수
- 다이나모DB(DynamoDB)의 테이블
아주 간단하게 기존의 RDB와 유사한 형태의 데이터를 집어넣어보겠습니다.
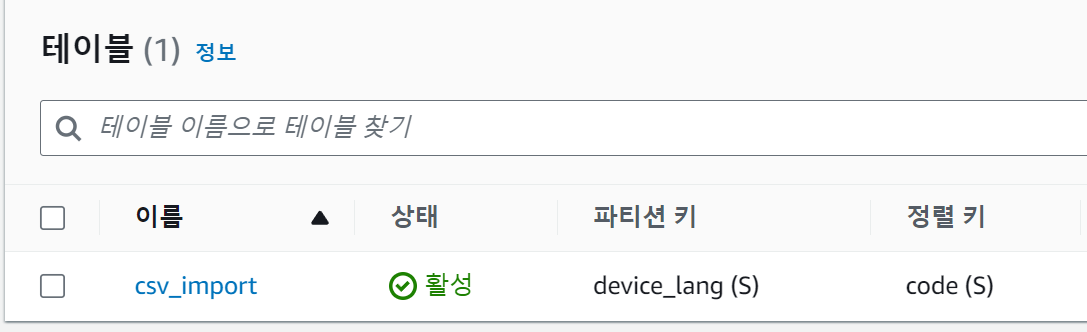
1. DynamoDB의 테이블을 먼저 정의합니다.
클라이언트의 언어 설정에 따라서 앱에서 표현될 언어 정보를 다이나모DB에 저장해둔다고 가정해봅시다.
파티션 키는 device_lang , 정렬키는 code (언어+국가 코드), 우선순위 priority, 각 언어별 설명 description 을 가진다고 설계했습니다. RDB 기준으로 4개의 컬럼이고 쭉 데이터가 있는 형태입니다.
아래는 실제의 샘플 데이터입니다. 데이터는 딱 4개만 설정했습니다.

DynamoDB에서 csv_import 라는 테이블을 미리 만들어주었습니다.
2. S3에 csv 파일을 올립니다.
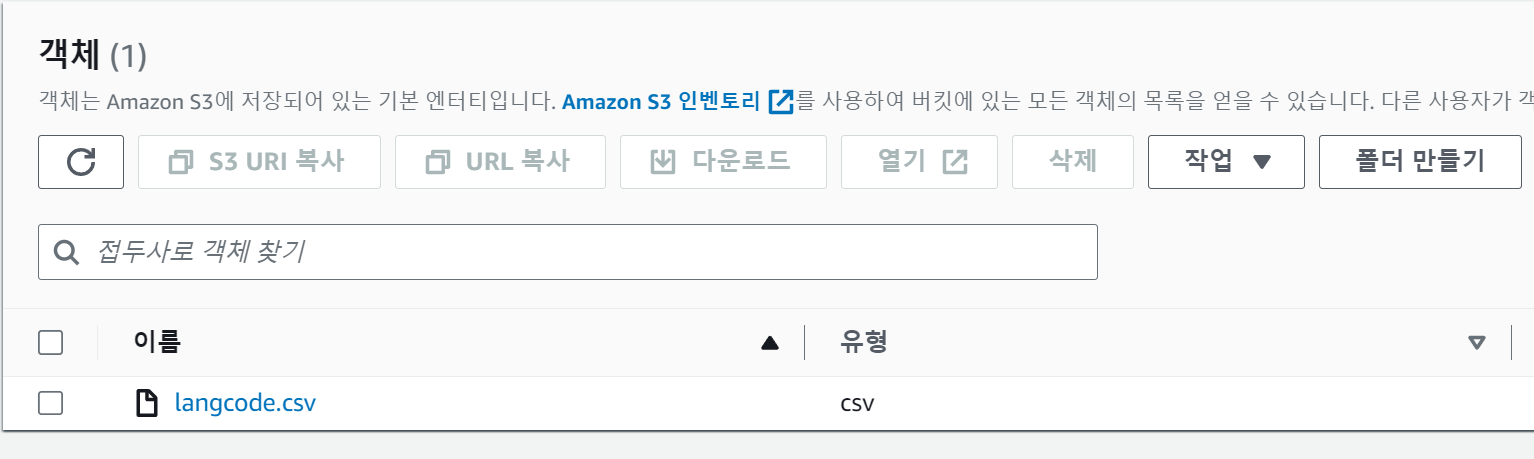
일단 csv-import-test1 이라는 S3 버킷을 만들어줍니다. (저는 빈 계정이기도하고, csv-import 만을 위한 버킷으로 이름을 지정해주었습니다.)

콘솔에서 직접 파일을 csv-import-test1 버킷에 업로드를 해줍니다. 저는 간단하게 파일명을 langcode.csv 로 했습니다.
3. 람다함수를 만들어봅시다.
람다함수에서 중요한 것은 S3에서 파일을 가져올 수 있는 권한과 다이나모DB에 접근할 수 있는 권한이 모두 필요합니다.
상세한 권한 정의를 하셔도 되겠지만, 일단은 모두 FullAccess를 주겠습니다.
미리 권한 정의를 해도 되고, 람다함수를 만든 뒤에 구성에서 직접 권한을 지정해주셔도 됩니다.
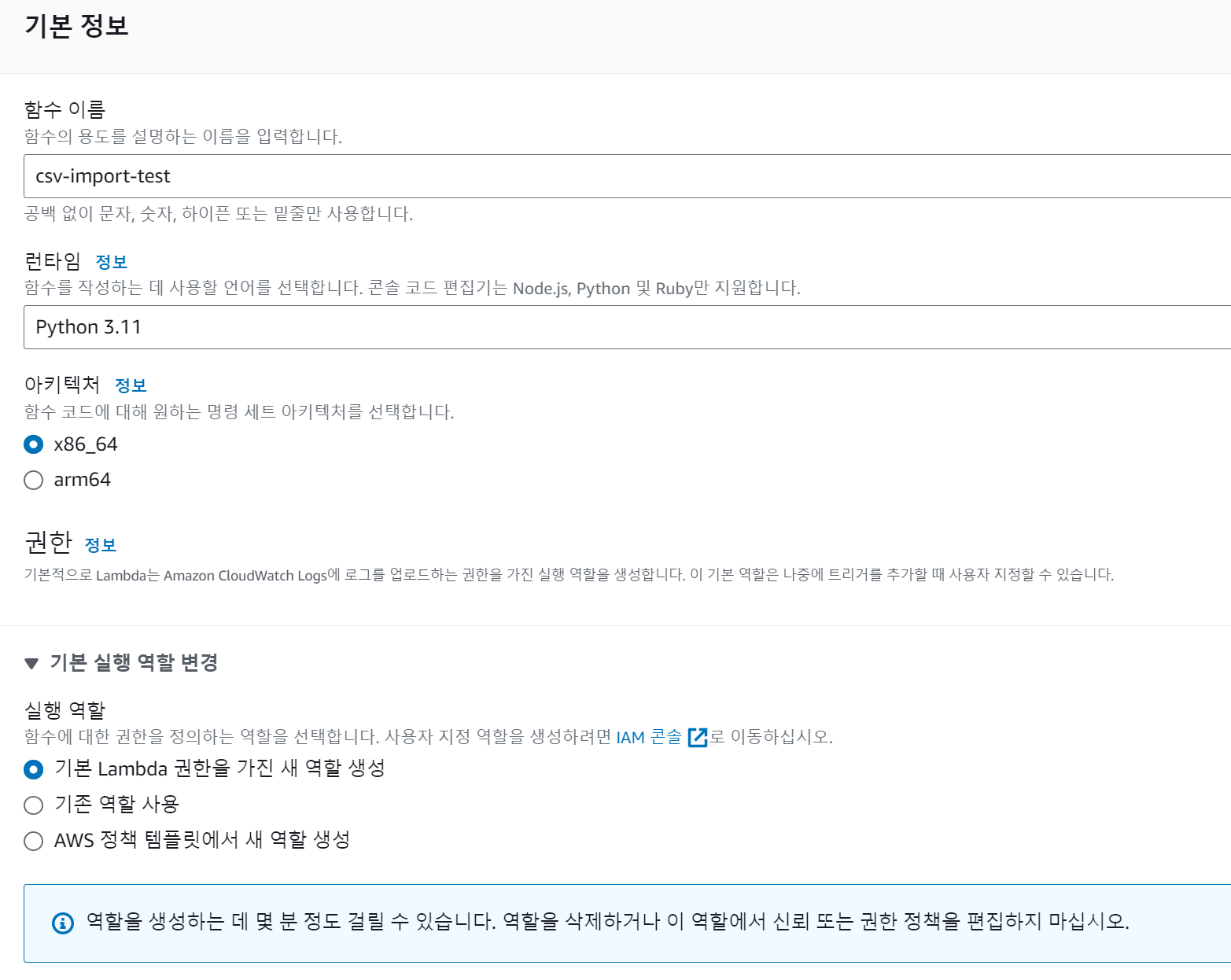
csv-import-test 라는 람다함수를 설정했습니다. (미리 s3, dynamodb 를 다루는 role 이 있으면 그것을 고르셔도 무방합니다. 아마 이렇게 쓰시는 분들은 저보다 AWS를 더 잘 아시겠죠?)
권한설정은 람다함수의 코드 편집화면 -> 구성 -> 권한 -> 실행 역할 -> 역할 이름을 누르면 새창이 뜨고 편집이 가능합니다

현재는 기본 람다함수 실행 권한만 있네요.
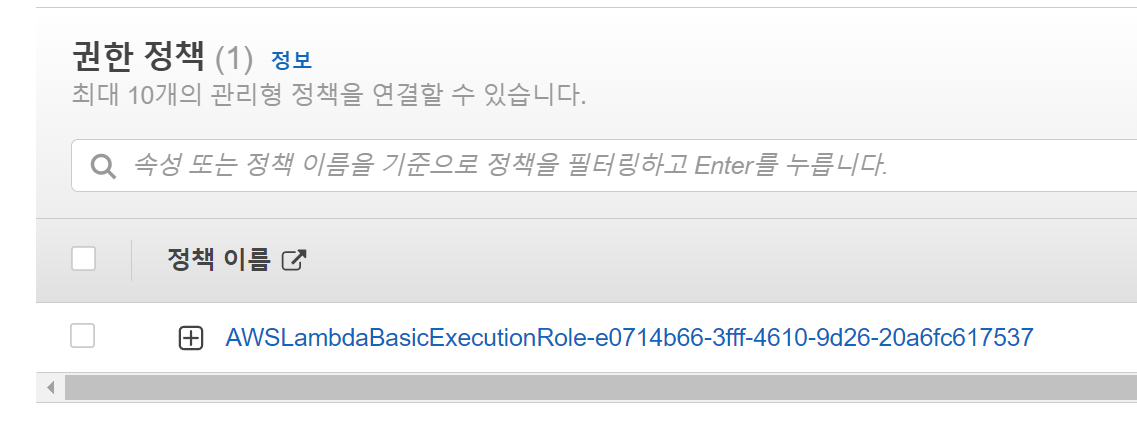
오른쪽 끝의 버튼을 눌러서 권한추가 -> 정책연결을 통해서 추가로 권한을 주어봅시다.
이제 S3, DynamoDB의 모든 기능들을 사용할 수 있습니다.
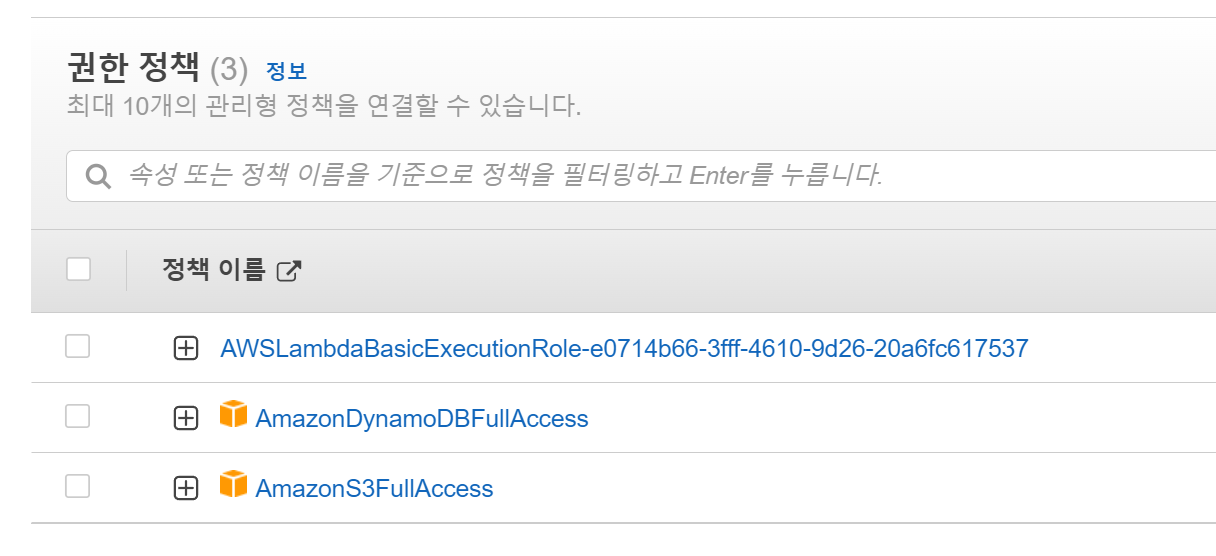
마지막으로 함수를 만들고 실행해보겠습니다. 그리 좋진 않지만, 적당히 돌아가는 형태의 구성입니다.
만약에 데이터의 구성이 복잡해지고, 자동화를 한다면 해야할 부분들은 추가될겁니다.
아래는 수동으로 지정된 파일의 데이터를 dynamodb에 입력하는 간단한 예제함수입니다.
예외처리, 데이터 구조 변경, 이벤트를 이용한 자동화 등등 추가적인 부분은 더 발전시켜보면 재미있을 것 같습니다.
import boto3
def lambda_handler(event, context):
s3_client = boto3.client("s3")
dynamodb = boto3.resource("dynamodb")
# dynamoDB 테이블명
table = dynamodb.Table("csv_import")
# bucket_name : 사용하고 싶은 버킷명 입력
# s3_file_name : 사용하고 싶은 s3_csv파일명(버킷을 기준으로 상대주소를 입력한다)
bucket_name = "csv-import-test1"
s3_file_name = "langcode.csv"
resp = s3_client.get_object(Bucket=bucket_name,Key=s3_file_name)
data = resp['Body'].read().decode("utf-8").strip()
rows = data.split("\n")
# 첫 줄의 헤더는 제외
success_count =0
fail_count = 0
for row in rows[1:]:
print(row)
row_data = row.split(",")
print(row_data)
# dynamodb에 입력
try:
# 테이블의 컬럼과 csv의 컬럼 짝 맞춰주기
# dynamodb 의 컬럼 이름을 입력합시다
table.put_item(
Item = {
"deviceLang" : row_data[0],
"code" : row_data[1],
"priority" : int(row_data[2]),
"description" : row_data[3]
}
)
success_count += 1
except Exception as e:
print(e)
print("End of file")
fail_count += 1
print(f"총 {len(rows)-1}줄 작업")
print(f"총 {success_count}줄 성공")
print(f"총 {fail_count}줄 실패")
실제 실행은 밖에서 람다함수를 호출할 수도 있고, 여기에서 직접 테스트해봐도 됩니다.
데이터 수작업을 하기 싫은 것 뿐이므로 간단하게 호출만 하는 테스트 함수를 정의해서 호출하겠습니다.
미리 test 라는 함수를 만들어두었습니다. 람다함수의 테스트 탭에서 진행하시면 됩니다.
아무런 호출을 받지 않으므로 따로 설정할 것은 없습니다.

다시 코드로 돌아와서 파란색 테스트 버튼을 눌러보면 실행이 되고 결과가 나옵니다.
람다의 기본값으로 실행하면 타임아웃이 날 수 있기 때문에 꼭 미리
구성 -> 일반 구성 -> 제한시간 (기본 3초) 을 늘려주셔야 합니다.

최종적으로 dynamodb에 저장된 모습은 다음과 같습니다.

4개의 데이터가 모두 잘 들어왔네요.
앞으로 데이터들을 좀 더 쉽게 넣어서 써봅시다. 수작업은 너무 힘드니까요~~
'Cloud > AWS' 카테고리의 다른 글
| AWS 람다에서 python으로 구글 시트 데이터 쓰기 (0) | 2025.02.16 |
|---|---|
| AWS에서 서버리스로 배치 기능 사용하기 (with EventBridge) - 기초편 (0) | 2024.07.01 |
| AWS 게이트웨이+람다에서 HTTPStatusCode 400을 설정해보기 (0) | 2023.11.05 |
| dynamodb 파이썬으로 데이터 스캔하기 (1) | 2023.10.28 |
| APIGateway 에서 람다로 데이터 전달하는 GET,POST 기본 템플릿 (0) | 2023.10.24 |


댓글